
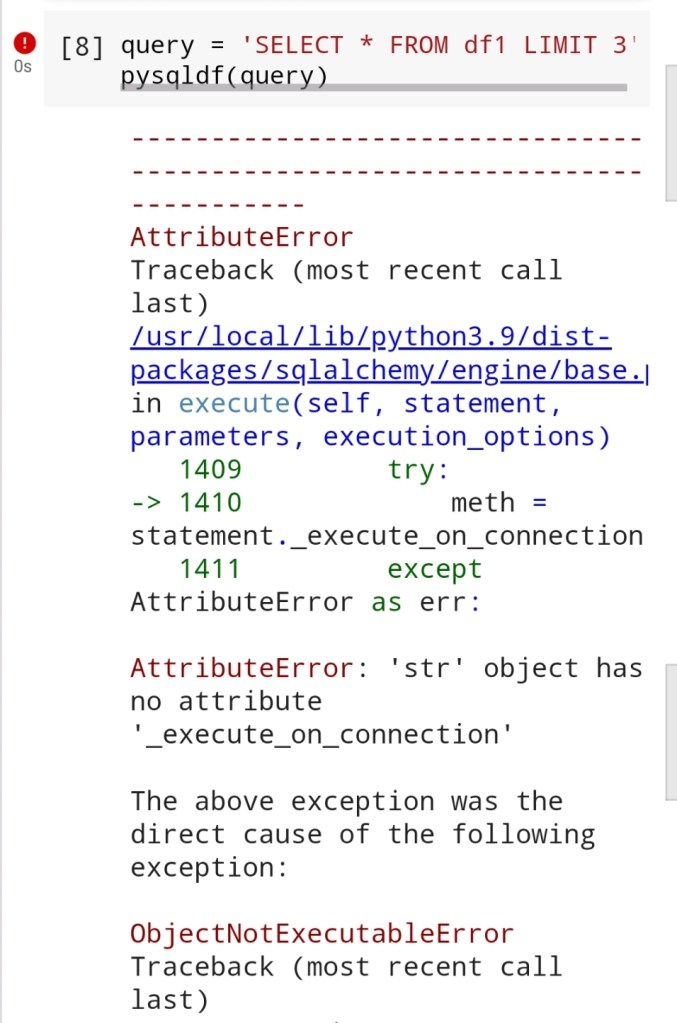
Last week a time-saving Python program I had been running successfully for several months in the Google Colab Jupyter notebook environment suddenly failed with a curious error.
The cause – an upgrade to a package (SQLAlchemy) that a library I was using (pandasql) depended upon had broken the library.
This was rather concerning since I had written a huge volume of code using the library and refactoring the code to do things a different way would have been a not insignificant undertaking.
Happily there are a couple of fixes. One is proposed in the link above which is to downgrade the package the broken library depends on before installing the library:
!pip install --upgrade 'sqlalchemy<2.0'
!pip install -U pandasql
This is not entirely satisfactory since one can imagine a time when that downgraded version is no longer supported.
Ideally a fix would be released to pandasql itself but despite its popularity and widespread use it seems no changes have been made to it for several years so what are the chances of that happening..
https://github.com/yhat/pandasql/issues/102
Alternatively, we can use a forked ‘fixed’ distribution of pandasql that someone has kindly created:
https://pypi.org/project/pansql
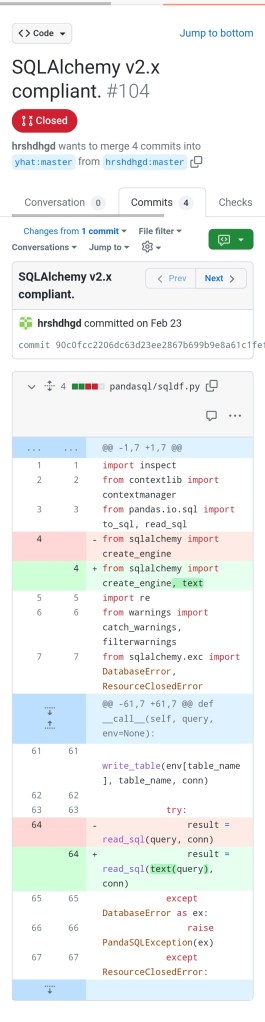
and simply install that fixed distribution (instead of pandasql) and then import the modules needed from it:
#!pip install -U pandasql
!pip install -U pansql
#from pandasql import sqldf
from pansql import sqldf
There may be debate about whether to use SQL and pandasql against dataframes, when other mechanisms to query their data are available:
https://www.reddit.com/r/bigdata/comments/oklwgk/pandasql_the_best_way_to_run_sql_queries_in_python/
Regardless of such stylistic, philosophical and aesthetic considerations, SQL remains one of the most established and popular languages for querying tabular data and rewriting existing code to use alternative methods, like the pandas query function can be time-consuming and will certainly require retesting.
I’ve experienced these unexpected failures of previously working code on occasion before e.g. where a package was completely removed from the base Colab distribution.
https://github.com/googlecolab/colabtools/issues/3347
Happily the community developed a fix in that instance too.
So, running Python programs on Google Colab’s ever changing foundation remains a rather nerve wracking experience with unexpected work being required from time to time when things suddenly break and you need to research, implement and test fixes. If you know a better approach to managing the relentless and inevitable changes to Colab please leave a comment!
